AdapterForPdfPid
Introduction
The intended purpose of the AdapterForPdfPid is to perform an extraction of data from different PDF files into a local. UPVP database. The AdapterForPdfPid scans PDFs and creates semi-intelligent P&IDs for use with the UniversalPlantViewer and UniversalPlantViewer Builder.
The program recognizes labels and sorts them into user defined categories like “equipment, piperuns, instruments etc.”.
The user defined categories must be put into an excel data sheet.
![]() The name of the created data sheet must be:
config.xlsx.
The name of the created data sheet must be:
config.xlsx.
An example of a config.xlsx can be found in .Files.
Graphical User Interface
After starting the AdapterForPdfPid on your device, the following window will appear:
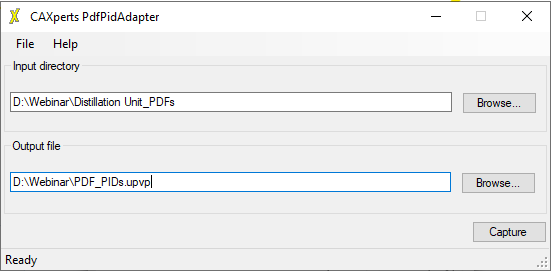
After locating the input directory and defining the output file the capturing process can begin.
![]() The created excel sheet with the name “config.xlsx” must be in the same
folder as the import PDFs.
The created excel sheet with the name “config.xlsx” must be in the same
folder as the import PDFs.
![]() Initiate this process by clicking the “Capture” button.
Initiate this process by clicking the “Capture” button.
Example
The following images show the process the AdapterForPdfPid goes through to generate semi-intelligent P&IDs.
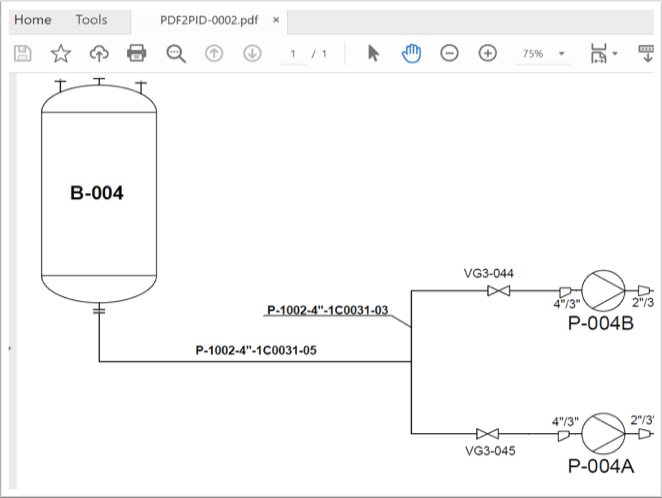
Example input PDF with tank, pumps, valves, lines and additional information:
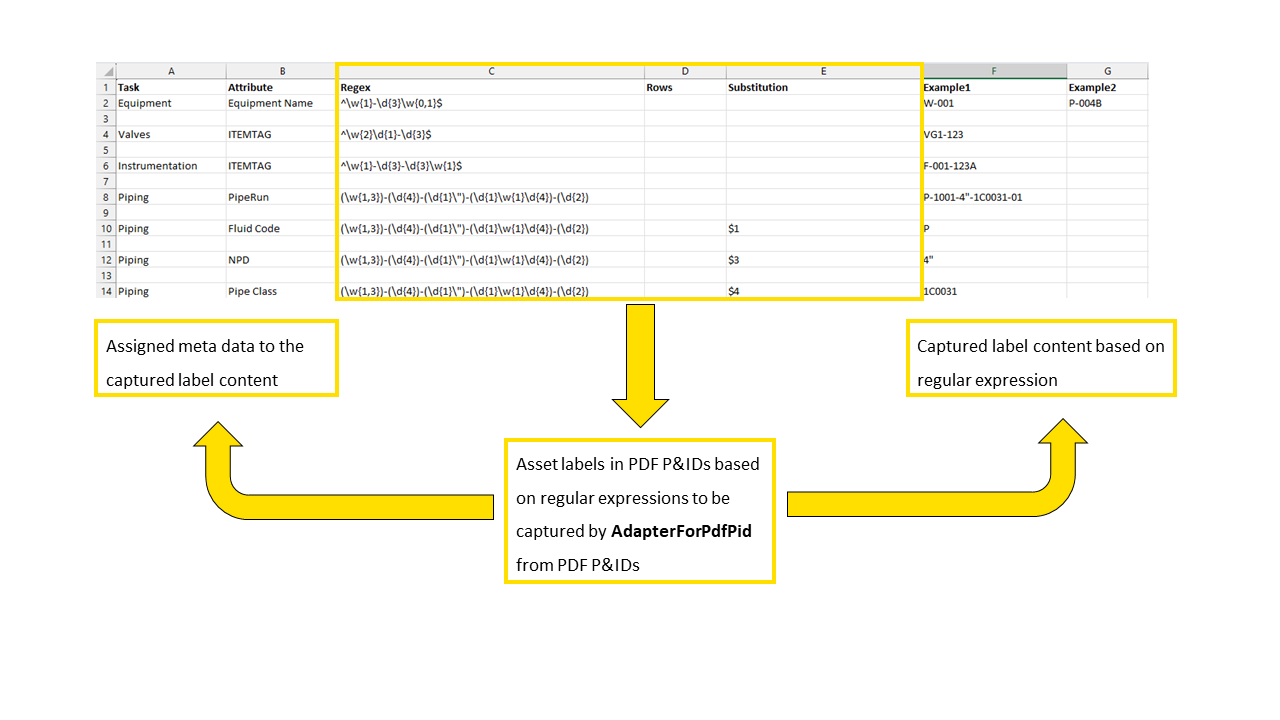
An extract of the resulting “config.xlsx” data sheet. This excel sheet contains relevant data to be collected from several input PDFs. The information is based on regular expressions (regex).
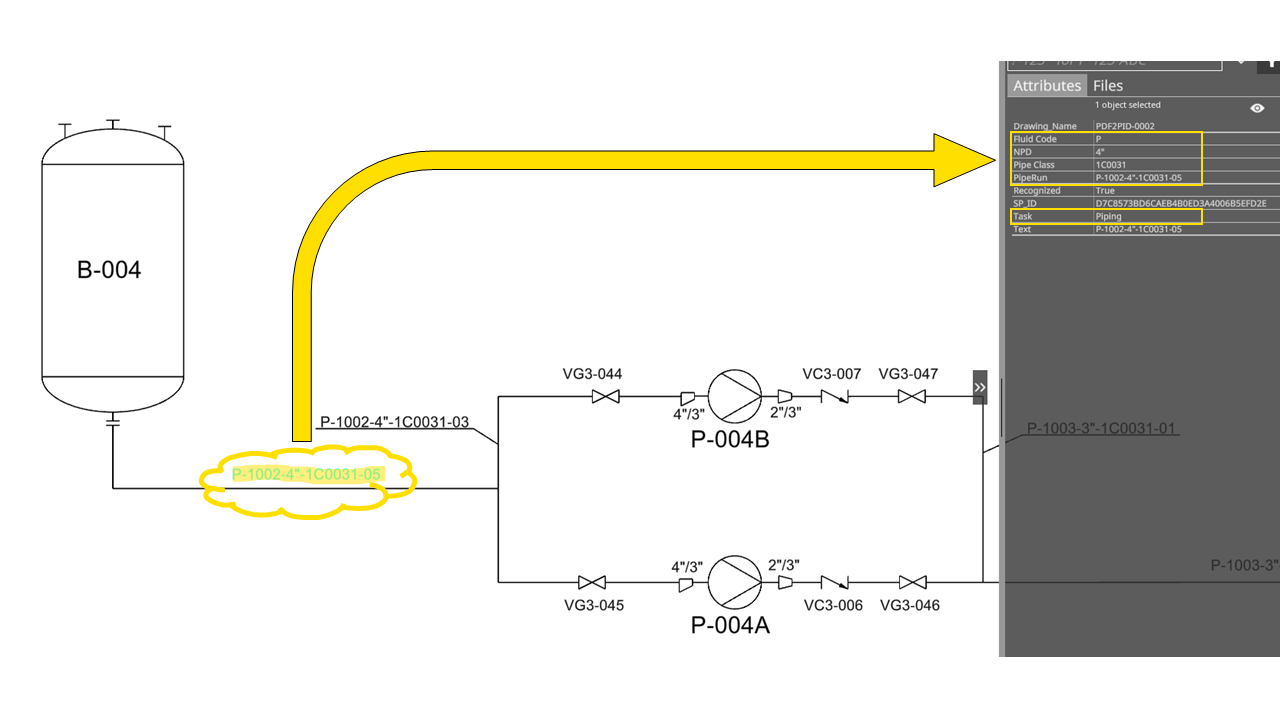
UniversalPlantViewer Builder
The result viewed in the UniversalPlantViewer / IntelliPID displays a full graphical representation as well as that main text labels are recognized as intelligent objects. In the following example, the semi-intelligent information is marked yellow.
![]() Keep in mind that the AdapterForPdfPid and the
UniversalPlantViewer Builder are intertwined through
the UniversalPlantViewer. For detailed information
click here!
Keep in mind that the AdapterForPdfPid and the
UniversalPlantViewer Builder are intertwined through
the UniversalPlantViewer. For detailed information
click here!
The PDFP&ID objects and the 3D objects can be linked using Mapping files. Additionally attributes can be loaded via the plugin UPVpluginExcelImport.